Proposed Data Collection
User-level data will be collected via Instagram for all factors. All users will have the option to voluntarily provide more detailed information about factors such as their demographics, past cyberbullying history, and current concerns. The primary limitation on data collection will be age.
Note: It is possible to derive certain predictors such as age from already existing data. Nevertheless, users will also be asked for these predictors and voluntary responses will be prioritized over inferred ones.
The following relations will be constructed.
Demographic
| Variable Name | Data Type | Collection Method |
|---|---|---|
| Age | Integer | Voluntary |
| Race | Categorical | Voluntary |
| Sexuality | Categorical | Voluntary |
| Household Income | Continuous Numeric | Voluntary |
| Gender | Categorical | Voluntary |
| User ID | Categorical | |
| Name | Categorical | |
| Physical Address | Categorical | Voluntary |
Cyberbullying History
| Variable Name | Data Type | Collection Method |
|---|---|---|
| Any past incidents | Boolean | Voluntary |
| Any reported past incidents | Boolean | |
| Number of Cyberbullying Experiences in Past Year | Continuous Numeric | Voluntary |
Network
| Variable Name | Data Type | Collection Method |
|---|---|---|
| Followers | Integer | |
| Following | Integer | |
| Frequency of Posting | Integer | |
| Frequency of Highlights and Stories | Integer | |
| Frequency of Comments | Integer | |
| Frequency of Direct Messages Sent | Integer | |
| Frequency of Direct Messages Received | Integer | |
| Cyberbullying in Online Circle | Boolean | Voluntary |
Direct Messages
The primary key for this table will be the other party and the data/time the message was sent. This will also include swipe ups from stories.
| Variable Name | Data Type | Collection Method |
|---|---|---|
| Other User Id(s) | Categorical | |
| Message | Categorical | |
| Date/Time Sent | DateTime |
Comments
| Variable Name | Data Type | Collection Method |
|---|---|---|
| Others User Id | Categorical | |
| Comment | Categorical | |
| Date/Time | DateTime | |
| Original Post Caption | Categorical |
Model
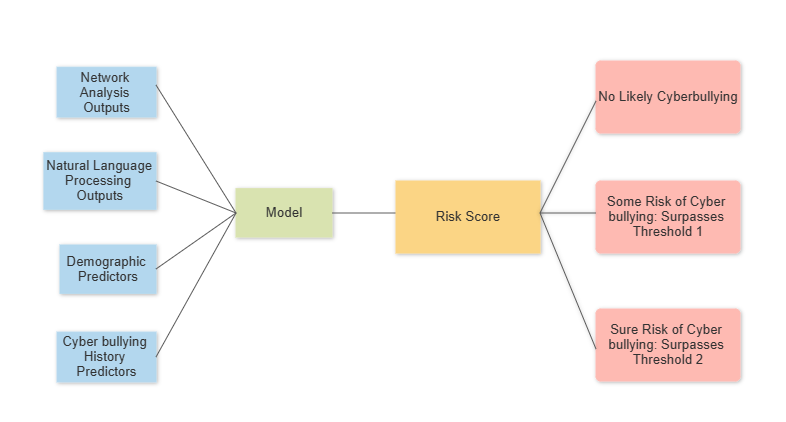
The predictors in demographic, cyberbullying history, and network relations will be used as inputs in the network analysis. The results of the network analysis will be statistics such as degree centrality, eigenvector centrality, and community membership. Degree centrality essentially measures the number of followers, which is relevant since more popular accounts may be more prone to cyberbullying due to more exposure. Eigenvector centrality measures a particular account’s influence in their network through measure such as time spent on viewing their posts or searching their account name. Community membership identifies particular groups who may belong to a marginalized group and be more likely to be targetted through cyberbullying.
We will also use natural language processing techniques on the predictors in the direct message and comments relations to predict whether a particular comment or message could be indicative of cyberbullying. The results of this subprocess can be statistics that reveal how many and the frequency of hostile comments, messages that a victim recieves and from who.
Finally, we will use the results from the subprocesses (i.g., degree centrality, frequency of hostile comments) the alongside the predictors in the demographic and cyberbullying history tables as inputs for our predictive model.
The model can take a variety of forms including logistic regression, decision trees, random forests, support vector machines, and neural networks. Since there are not strong existing biases within this data, we will prioritize performance above transparency and choose a neural network model to optimize performance.
The result of the model will be a score from a scale of 1 to 100, where a higher score indicates one is more likely to be a victim.
There will be 2 thresholds used to classify each score. The thresholds will be determined based off of the training data and the outcomes of cyberbullying incidents examined manually by the Instagram team.
If a score surpasses the first threshold, then the victim is warned and provided with educational resources and reminded of actions they can take including blocking and flagging accounts. If there are other account holders or if the account has parental controls, then the parents will be notified.
If a score surpasses the second threshold, then actions that were recommended to the victim are automatically done, a real person from the Instagram team is notified to look more into the case, and the victim will be notified. For example, an account that consistently sends inappropriate messages will be blocked unless the user unblocks them manually. If there are inconsistencies with this process, the original user can also submit feedback anytime as a false flag.
Measurement System
There are two primary components of the measurement system: how we plan to measure each variable and how well our variables represent the knowledge we hope to extract.
First, predictors within the direct messages and comments relations are most likely to suffer from measurement bias since there are discrepancies between how younger and older teenagers communicate and and the model may not fully encapsulate colloquialism and context. To combat this, it is vital that training data is representative of teens of different ages, locations, and cultures across the US. Additionally, the training data should be updated consistently to keep up with slang and evolution. The time frame for colloquialism’s change varies and depends upon many factors. Although conservative, we recommend the model be retrained every year with updated data. For other factors, if voluntary data is missing, we ought to be able to accurately impute those values based on the profile Instagram has of the user and missingness techniques.
The second component of the measurement system and potential bias is how well each predictor represents the true knowledge we hope to extract. For example, how well does the number of average comments on one’s post represent the influence of a particular user? There is no technical measurement for this, and to prevent this bias from being a significant barrier, the model makers ought to work with domain experts to ensure that the proxies are consistent with the project goal.
Consent
By signing up for Instagram, users allow Instagram to monitor many factors, including many of the predictors outlined, as well as create a profile on them. Therefore, their data will be used in the training model through the same privacy measures they agreed to when signing up for Instagram. Since this project serves as an additional feature on Instagram, if a user chooses to use this feature, they will be encouraged to provide additional information about themselves with educational consent. They will be explained why specific predictors are requested and what the purpose is.
Users can opt in or opt-out of this feature. If a user creates a new account or is young, Instagram will recommend they turn the feature on.